Introduction to Statistical Computing
👨💻 Eugene Hickey @ Atlantic Technological University 👨💻
- eugene.hickey@tudublin.ie
- @eugene100hickey
- github.com/eugene100hickey
- www.fizzics.ie
Week One
Welcome to the course on statistical computing.
We will discuss how to make the most of your data.
Complimentary to the qualitative analysis you do with Emma.
Goal here is to provides skills in data analysis.
We’ll learn to use a software system called R.
Acknowledgments



Ruth Moran, co-pilot for this workshop Graduate Research & Education Training Officer.
slides produced using quarto
assessments produced using Rexams
Target Audience
Graduate students looking for better ways to present their data.
People currently using tools like MS Excel for analysis.
Why R?
Working with a mouse isn’t reproducible
- difficult to log exactly what you’ve done
- hard to repeat for a series of analyses
- difficult to be inspired by other people’s work
Good to separate sources of data from the analysis
R uses series of commands that input, manipulate, and display data
Lots of contributors around the globe, diverse fields
- this is the world of open source software
Course Outline
Introduction to Statistical Computing & R - Saturday April 5th
Statistical Inference - Saturday April 12th
Manipulating Data - Saturday April 26th
Getting and Cleaning Data - Saturday May ??
Data Visualisation - Saturday June ??
Stuff we won’t be doing
creating functions, iterating
R is cracker at machine learning
also great at making documents and presentations using quarto
and websites and blogs
Assessment
- Weekly online quizzes
- get three attempts
- best mark from the three
- some multiple choice, some open answer
- based on this weeks lecture
- Exercises to be done within R
- these are called
swirl() - email results to me (screenshot of final page is fine)
- these are called
- Project at end of course
- somewhat optional, can either do one on Emma’s section or on this part, or a combination
- best to do something associated with your research that can be useful beyond this module
Resources
Books
- recommended text
- Hadley’s book, R for Data Science
- The Epidemiologist R Handbook
- Data Science in Education Using R
- Fundamentals of Data Visualization by Wilke, lots of his actual code is on github at https://github.com/clauswilke/practical_ggplot2
- Data Visualization by Kieran Healy (ISBN = 978-0691181622). ~€25. Also online at https://socviz.co/index.html
- check out the list of online books at bookdown.org

Websites
Karl Broman (https://www.biostat.wisc.edu/~kbroman/), and particularly this presentation
course by Boemhke on github github.com/uc-r/Intro-R
the good people at RStudio have lots of help at https://posit.co/
The R Graph Gallery is pretty good and worth checking out

Blogs and Podcasts

Online Courses
Coursera: Data Science from Johns Hopkins. The course notes are on github
edx.org course from Irizarry

Miscellaneous
RWeekly.org, round up of events in the world of R
#Rstats on twitter Mastodon
#TidyTuesday on twitter
if you get stuck, google is your friend. Often sends you to stackoverflow.com or stackexchange.com
Installing R and RStudio
first R from CRAN
- R is the engine
then RStudio from Posit
- RStudio is the cockpit
alternative is to make an account at Posit Cloud
- give 25 hours per month
R is case sensitive
This is a nice tutorial suite to explain installing R and RStudio:
RStudio Screen
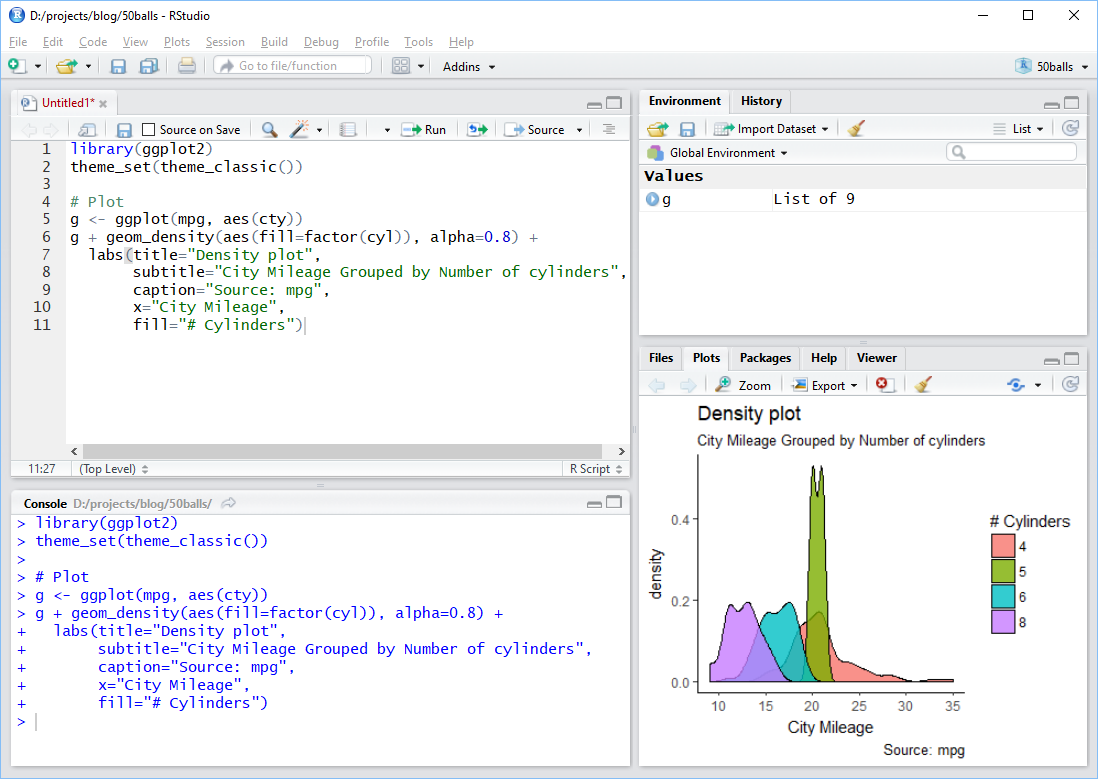
Using RStudio
- toolbar across the top
- I don’t use this very much
- set of quick links below that
- top left (green plus sign) is about the only one I use
- 4 Panes
- top left for files or looking at data
- bottom left for the console
- top right for Environment - tells what variables are stored
- bottom right for plots and help
Using RStudio (continued)
- usual work flow is:
- try commands out at the console (bottom left)
- when that works, store them in a file (top left)
- when sequence of commands works, put them into a document (also top left)
Extending R
- installing R just gives you base R
- beauty of this tool lies with packages 📦
- we’ll look at installing these from three sources:
- CRAN
- Bioconductor
- github
CRAN
- CRAN
- example, on console type
install.packages("palmerpenguins") - this installs the palmerpenguins package (we’ll need this for this week’s quiz)
- over 20k packages on CRAN (see list here)
- sometimes esoteric (engsoccerdata)
- sometimes cutting edge (deep learning)
- each package heavily curated and maintained
- Task Views good place to start looking
- example, on console type
Bioconductor
- Bioconductor
- set of bioinformatics packages (lots of genomics)
- start with
install.packages("BiocManager") - then
BiocManager::install("some_genomics_package")to use - list of packages here
- about 3,000 packages, including genome builds
Github
- github
- packages in development
- start with
install.packages("devtools") - then
devtools::install_github("developer_name/package_name") - almost 80k packages here
- the package githubinstall is useful to search these
Installing Packages
- try
install.packages("scales")- will add functions from someone else’s work so you can use it
- need to do this just once
- to actually make this available, type
library(scales) - do this every time you start R and want to use scales package
- one package we’ll need is tidyverse,
install.packages("tidyverse")- this might take a few minutes because such a large collection of packages
- Using the Console
- Storing Values
- Fundamental Data Types
- The Dataframe - Rows \(\times\) Columns
- Dataframe Columns
- Subsets of Dataframes
- Small Useful Functions
Using the Console
- R is a calculator
- can type, say,
45 + 17and get the answer back - * is multiply, / is divide
- get constants like pi for \(\pi\)
- can run functions from the console like, say,
sqrt(x=49)(or justsqrt(49)) - can get help on these functions by typing, say,
?sqrt - to get list of help in the base package try
base::and then press tab
Storing Values
- results of calculations can be stored
- do this with
my_square_root_result <- sqrt(49) - the
<-reads as gets (can also us equals sign, =, but that’s sloppy) - keyboard short cut for <- is alt and - simultaneously
- full list of RStudio shortcuts in Help on the toolbar (ironically, of course, there is a keyboard shortcut for keyboard shortcuts help)
- list of stored values given in the Environment tab of RStudio
Fundamental Data Types
- numeric (or double) is for numbers with decimals. Default for numbers.
- integer for counting numbers. Type in
x <- 72Lto get integer 72 - logical gives TRUE and FALSE
- character gives text. Try typing
x <- "I am Groot".- Equivalent is
x <- 'I am Groot'
- Equivalent is
- complex is for stuff like 14 + 3i. I’ve never used these. Ironically
sqrt(-1)gives an error rather than i - factor. These deserve fuller explanation and get a slide of their own.
Factors
- super useful when only limited number of possible values for a variable
- examples like female / male or Alabama / Alaska / …. Wyoming
- possible values are called levels
- levels have an order, default is alphabetical but can adjust this
- forcats package in the tidyverse deals with factors
- have big impact on figures
- figures will look different depending on whether a variable is a factor or a character
- legend will be in the order of levels of a factor
- can change between data types using the as. functions
- e.g.
as.character(),as.numeric() - check out all the function in forcats for dealing with factors
- e.g.
- can figure out the data type using the
class()function
Data Frames
- these are the workhorse of R data types
- look like spreadsheets
- we’ll work with them a lot
- organised by rows (across) and columns (down)
- each column must have the same type
- can examine data frames using the
View()function (note, capital “V”) - can find column names using the
names()function - related concepts are tibbles and data.tables
Subsets of Data Frames
- can access individual column elements by specifying the row and column position
- e.g.
mtcars[2, 5]is the 2nd row of the fifth column
- e.g.
- can access an entire row by leaving the column part blank
- e.g.
mtcars[2, ]is the whole 2nd row
- e.g.
- likewise get the entire column by leaving the row slot empty
- e.g.
mtcars[,5]is the entire 5th column
- e.g.
Subsets of Data Frames
- can also access columns using the dollar sign, $
- e.g.
mtcars$cylgives the 2nd column, called cyl
- note
mtcars$cyl[2]gives the second element of this
- e.g.
- can use a number range using : to get a bunch of values
- e.g.
mtcars[1:4, 2:4]takes a chunk of the mtcars data frame
- e.g.
Lists
dataframes have constraints
all columns must be the same type
rows and columns must be the same length
listsare more generalexample,
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2), list("green",12.3))list_data[[1]]gives the three months, etc- note the double square bracket,
[[ ]]
- note the double square bracket,
Some Useful Functions
c()let’s you create a vector of quantities. Coerced to same typeis.na()to check if a missing value,sum(is.na())gives total of thesedim()gives number of rows / columns in data frame, alsolength()class()for nature of variablesummary(),str(),glimpse()show data frame parameters. Alsoskim()from the skimr package- I use
%in%quite a bit, checks if value is among a bunch of values"August" %in% month.name"£" %in% letters
Some Useful Functions
Sys.date(),Sys.time()ls()gives list of variablesfile.list()gives list of filessessionInfo()tells you what packages are loadedcitation()tells you about a packagemean()calculates mean of a vector,sd()the standard deviationcomplete.cases()returnsTRUEif there are no missing values in a row
And Some Weird Characters
- get to use a lot of the keyboard in R
- we’ve seen
$to extract a column of a data frame ()are arguments to functions[]are gateways to data frame elements%>%is called the pipe and is really cool. Ctrl + Shift + M shortcut- some logical operators:
!is NOT,|(or||) is OR,&(or&&) is AND
- we’ve seen
Workshop - Week One
Perform the Following Tasks:
multiply the numbers \(25\times \pi\) and save the result to my_first_result
make a vector of five numbers e.g. 34.1, 54.4, 71.5, 93.8, 22.6 and save them to my_second_result
multiply my_second_result by 7 and print the results
print the
airqualitydatasetexamine the
airqualitydataset usingsummary(),str(), andglimpse(). For the latter you’ll need the tidyverse library.store the values of
Tempfrom theairqualitydataset in a new variable you can calltemperaturecalculate the
mean()oftemperaturecalculate the standard deviation,
sd(), oftemperaturefind the names of the columns in the
Puromycindatasetlook up the help for the
USJudgeRatingsdataset and find out what is meant by the “DECI” column nameinstall and load up the package dslabs. Use
is.na()andsum()to find the number of missing values in theus_contagious_diseasesdatasetwhat kind of variable is stored in
olive$area?what are the levels of the factor in
olive$region?
Assignments - Week One
Complete week one moodle quiz
Complete
swirl()exercises
install.packages("swirl")library(swirl)install_course("R Programming E")swirl()choose course R Programming: The basics of programming in R
do the four exercises 1 (basic Building Blocks) to 4 (Vectors)
email the results to eugene.hickey@associate.atu.ie